Self-Diagnosing CI: Auto-Creating Jira Tickets and Running a Playwright Healer Agent in GitHub Actions
A CI test failure on its own tells you almost nothing useful. You get a red badge, a vague “3 tests failed” notification, and the implicit expectation that someone will eventually dig into the logs and figure out what happened. In a project where the test suite covers a Streamlit application backed by a six-agent AI pipeline, “someone eventually digging in” wasn’t going to be sustainable.
I wanted two things: a Jira ticket created automatically whenever the Playwright suite failed, with enough detail to triage without opening the Actions log; and a healer agent that would attempt to diagnose and fix the failing tests before a human even saw the notification. The implementation took about a week of iterative debugging, and the journey from initial commit to something reliable taught me more about the limits of agentic code generation than the feature itself.
Part One: Auto-Creating Jira Tickets
The starting point was a Node script — scripts/create-jira-failure.js — that the workflow runs after test failure. The Jira Cloud REST API v3 uses Atlassian Document Format (ADF) for rich text rather than plain Markdown, which means building a JSON document tree rather than formatting a string:
function buildDescription(failures, runUrl) {
return {
type: 'doc',
version: 1,
content: [
{
type: 'paragraph',
content: [
{ type: 'text', text: 'GitHub Actions run: ' },
{ type: 'text', text: runUrl,
marks: [{ type: 'link', attrs: { href: runUrl } }] },
],
},
{
type: 'bulletList',
content: failures.map(f => ({
type: 'listItem',
content: [{ type: 'paragraph', content: [
{ type: 'text', text: f.title, marks: [{ type: 'strong' }] },
{ type: 'hardBreak' },
{ type: 'text', text: f.error, marks: [{ type: 'code' }] },
]}],
})),
},
],
};
}The script reads test-results/results.json (written by Playwright’s JSON reporter), extracts the failed test titles and error messages, creates a Bug issue via the REST API, and then attaches the raw screenshots, traces, and results JSON as file attachments. The issue key gets written to $GITHUB_OUTPUT so downstream steps can reference it.
The result is a structured Bug ticket with a clickable Actions run link and one bullet per failed test, each showing the title and a truncated error message:
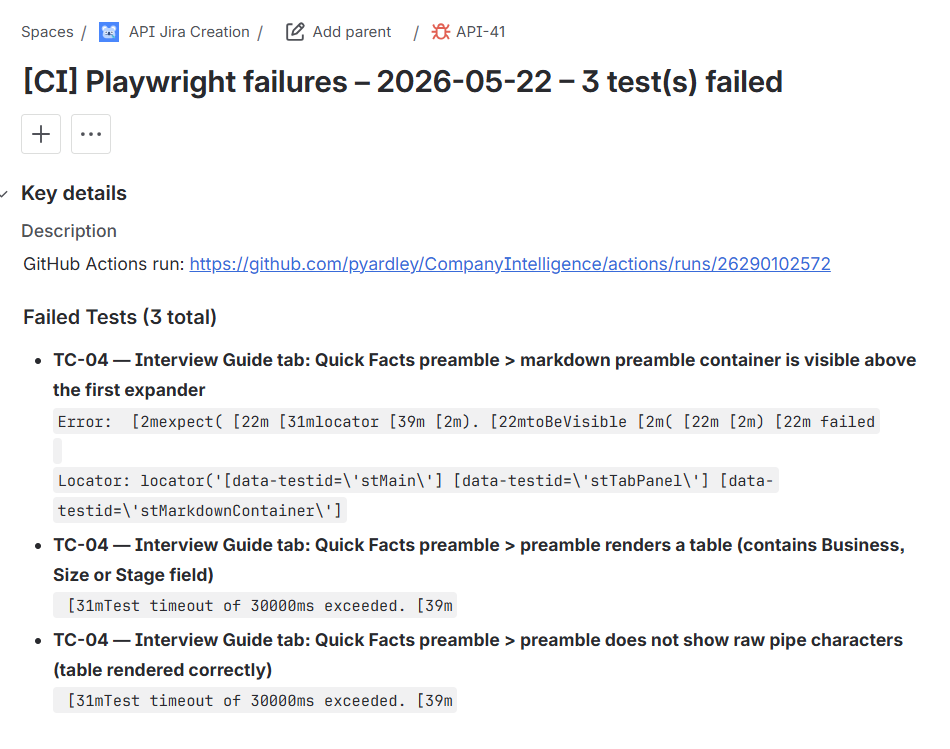
Screenshots, traces, and the raw results.json are attached automatically so anyone triaging the ticket has everything they need without opening the Actions log:
The workflow step is straightforward:
- name: Create Jira ticket on test failure
id: create-jira
if: failure()
env:
JIRA_BASE_URL: ${{ secrets.JIRA_BASE_URL }}
JIRA_EMAIL: ${{ secrets.JIRA_EMAIL }}
JIRA_TOKEN: ${{ secrets.JIRA_TOKEN }}
JIRA_PROJECT_KEY: ${{ secrets.JIRA_PROJECT_KEY }}
GITHUB_RUN_URL: ${{ github.server_url }}/${{ github.repository }}/actions/runs/${{ github.run_id }}
run: node scripts/create-jira-failure.jsThe Fixes the Initial Version Needed
The first iteration worked locally but failed in CI in three distinct ways.
CommonJS in a project expecting ES modules. The initial script used require(), but package.json had "type": "module", making every file implicitly an ES module. The fix was a single change to imports and a #!/usr/bin/env node shebang that doesn’t help with module type — the actual fix was converting to import syntax:
// Before
const fs = require('fs');
const path = require('path');
// After
import fs from 'fs';
import path from 'path';Description truncation. Jira’s REST API has a hard 32,767 character limit on the description field. A test suite with many failures — especially ones with long stack traces — could easily exceed this. The fix was capping error messages per failure (errorMsg.slice(0, 200)) and limiting the number of failures shown in the description to twenty, with an overflow notice pointing to the attached results JSON.
Suite-level errors not creating tickets. If Playwright itself fails before any tests run — a global setup error, a missing dependency, a configuration problem — report.suites is empty but report.errors is populated. The original script checked only for failures.length > 0 before creating a ticket, which meant a completely broken suite produced no Jira issue at all. The fix was checking globalErrors = report.errors ?? [] alongside individual test failures and creating a ticket for either.
Part Two: The Playwright Healer Agent
Once the Jira ticket creation was working, the next step was adding an agent to attempt automatic repair. The idea: when tests fail, run Claude Code in --print mode against a prompt that describes the job, and pipe its output into a healer-result.md that gets posted as a comment on the newly-created ticket.
The initial workflow step looked like this:
- name: Run Playwright Healer Agent (on failure)
id: healer
if: failure() && steps.tests.outcome == 'failure'
run: |
echo "Tests failed. Starting Playwright Healer Agent..."
npm install -g @anthropic-ai/claude-code
claude --dangerously-skip-permissions \
-p "$(cat .github/prompts/healer-prompt.md)" \
--model claude-sonnet-4-5 \
> healer-result.md 2>&1
echo "Healer completed."
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
CI_BASE_URL: http://localhost:8501And scripts/add-jira-comment.js reads healer-result.md and posts it as a comment using the same ADF structure:
function buildCommentBody(text) {
return {
body: {
type: 'doc', version: 1,
content: [{
type: 'codeBlock',
attrs: { language: 'markdown' },
content: [{ type: 'text', text }],
}],
},
};
}When the healer completes, the comment appears on the ticket as a code block containing the full diff and a status summary:
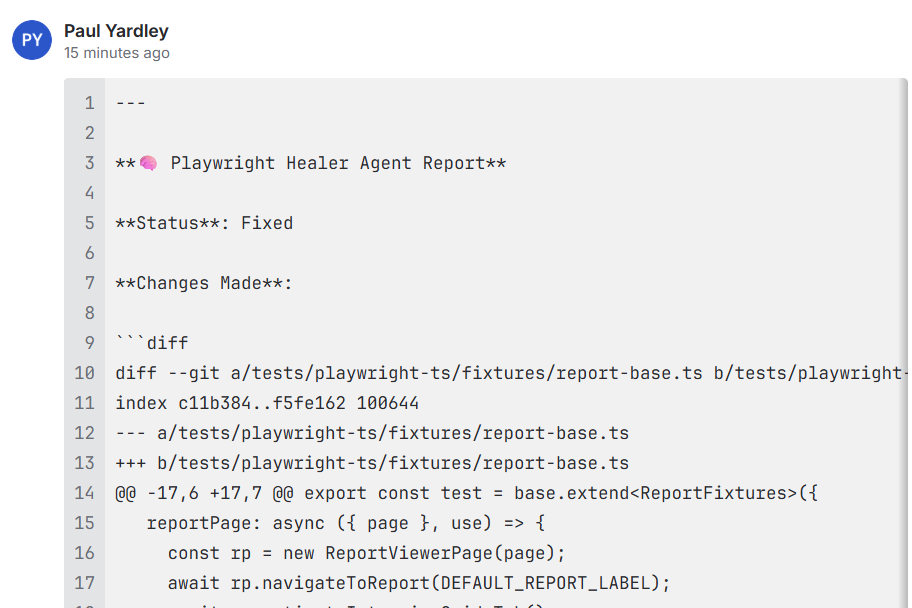
This part of the system produced five consecutive CI failures before it worked reliably. Each failure was a different bug.
Fix 1: Wrong Model Name
The initial implementation specified --model claude-sonnet-4-5. That model doesn’t exist — the correct identifier is claude-sonnet-4-6. The error was silent until runtime: the workflow step failed with a model-not-found error, which meant the healer step showed as failed, which meant the Add Healer Comment to Jira step’s condition (steps.healer.outcome == 'success') was never met, and no comment was posted. A one-character fix — 4-5 to 4-6 — but it required a failed CI run to surface it.
Fix 2: Rate Limit at 30,000 Input Tokens Per Minute
With the model name corrected, the healer ran — for sixteen minutes — and then died with this:
Error: Request rejected (429) · This request would exceed your organization's
rate limit of 30,000 input tokens per minuteClaude Code in agentic mode makes many sequential API calls. Each turn grows the context window as prior tool calls and responses accumulate. After sixteen minutes of successful calls, one request finally pushed the rolling-minute token count over the org-level limit.
The 30,000 TPM limit is below the standard Tier 1 rate for claude-sonnet-4-6 (which starts at 40k). Three things needed fixing: the model, the turn limit, and the step timeout.
Switching to claude-haiku-4-5-20251001 addressed the rate limit directly — Haiku is cheaper and has a higher effective rate limit at the same account tier. Adding --max-turns 15 capped the loop. Adding timeout-minutes: 10 to the step prevented it from blocking the entire job if the agent went sideways.
claude --dangerously-skip-permissions \
-p "$(cat .github/prompts/healer-prompt.md)" \
--max-turns 15 \
--model claude-haiku-4-5-20251001 \
2>&1 | tee healer-result.mdFix 3: Max-Turns Exit Code Causes Step Failure
With --max-turns 15, Claude Code exits with code 1 when the limit is reached — Error: Reached max turns (15). This caused the step itself to fail, setting steps.healer.outcome to 'failure', which again prevented the Jira comment from being posted even though healer-result.md had content.
The fix was a || echo fallback that absorbs the non-zero exit and keeps the step green:
claude ... 2>&1 | tee healer-result.md \
|| echo "Healer exited non-zero (max turns or error) — partial output saved."With set -o pipefail already set, the || applies to the entire pipeline. If claude exits with code 1, the echo runs and exits 0, the step succeeds, and the Jira comment step fires.
Fix 4: No Output — Buffering and the 10-Minute Timeout
After raising max-turns to 25 (15 wasn’t enough for a complete healer cycle), the next run hit the 10-minute step timeout with zero output — not even healer-result.md is empty or missing. The log showed:
Tests failed. Starting Playwright Healer Agent...
added 2 packages in 3s
Error: The action 'Run Playwright Healer Agent (on failure)' has timed out after 10 minutes.Two things were wrong. First, Claude Code in --print mode (-p) runs the full agentic loop and buffers its stdout until completion. With a 10-minute timeout killing the process, nothing had been flushed to tee yet. The fix was stdbuf -oL on both sides of the pipe to force line-by-line flushing, plus --verbose on the claude command to produce per-turn progress output rather than silence:
stdbuf -oL claude --dangerously-skip-permissions \
--verbose \
-p "$(cat .github/prompts/healer-prompt.md)" \
--max-turns 25 \
--model claude-haiku-4-5-20251001 \
2>&1 | stdbuf -oL tee healer-result.mdSecond, the cat healer-result.md echo at the end of the step’s run block never executed because the step timeout kills the entire block. Moving the print to a separate step with if: always() ensures it runs regardless of the healer outcome:
- name: Print healer output
if: always()
run: |
echo "=== Healer Agent Output ==="
if [ -f healer-result.md ]; then
echo "File size: $(wc -c < healer-result.md) bytes"
cat healer-result.md
else
echo "(healer-result.md not found)"
fiFix 5: The results.json Race Condition
Alongside the healer problems, the Jira ticket creation step started reporting No results file found; skipping Jira ticket creation even when three tests had visibly failed. The root cause was a race condition introduced by the healer itself.
The healer’s prompt included an instruction to re-run the failing tests after applying a fix. Playwright, when run, clears the test-results/ output directory before writing new results. If the healer ran npx playwright test and the step then got killed by the 10-minute timeout mid-run, test-results/results.json was deleted at the start of the re-run but never written — because the run was killed before it completed.
The Jira script ran after the healer and found an empty test-results/ directory.
The fix was reordering the workflow steps so that uploads and Jira ticket creation happen before the healer runs:
# Original order (broken)
Run tests → Healer → Upload artifacts → Create Jira ticket
# Fixed order
Run tests → Upload artifacts → Create Jira ticket → Healer → Post healer commentWith this ordering, the original results.json is consumed and uploaded before the healer has any opportunity to touch it. The healer can overwrite whatever it likes — the ticket already exists.
Part Three: The TC-04 Healer Report — Where It Helped and Where It Fell Short
With the infrastructure problems resolved, the healer ran against a genuine test failure: three TC-04 tests in report-guide.spec.ts failing with element(s) not found when trying to find quickFactsContainer. The healer’s report was technically correct and genuinely useful — but one of its two fixes was the wrong shape.
The healer correctly identified both root causes.
Root cause one was that the reportPage fixture was documented as “Navigated to the default report, Interview Guide tab active” but never actually called activateInterviewGuideTab(). The healer proposed adding the call, matching the fixture to its documented intent:
// report-base.ts — healer's proposed fix (applied unchanged)
reportPage: async ({ page }, use) => {
const rp = new ReportViewerPage(page);
await rp.navigateToReport(DEFAULT_REPORT_LABEL);
await rp.activateInterviewGuideTab(); // added
await use(rp);
},This was correct and was applied as-is.
Root cause two was that the quickFactsContainer locator used a hasNot: style filter to exclude markdown containers with <style> children:
this.quickFactsContainer = page
.locator("[data-testid='stMain'] [data-testid='stTabPanel'] [data-testid='stMarkdownContainer']")
.filter({ hasNot: page.locator('style') })
.first();Streamlit now injects a <style> element into every stMarkdownContainer — not just CSS injection containers — so the filter eliminates all results. The healer correctly identified this as the cause of “element(s) not found.”
Its proposed fix, however, was:
// Healer's proposed fix — not applied
this.quickFactsContainer = page
.locator("[data-testid='stMain'] [data-testid='stMarkdownContainer']")
.nth(4);This works. The healer verified “All 16 tests in report-guide.spec.ts now pass.” But .nth(4) is fragile in a way the healer’s fix isn’t. It drops the stTabPanel scope entirely and selects the fifth markdown container on the page by absolute DOM index — skipping what the healer correctly identified as CSS injection (index 0), success banner (index 1), and two tab labels (indices 2 and 3). Add a third tab to the app, and Quick Facts jumps to .nth(5). The fix would silently break.
The better fix — and the one actually applied — was to remove only the broken filter while keeping the stTabPanel scope that was already doing the heavy lifting:
// Applied fix
this.quickFactsContainer = page
.locator("[data-testid='stMain'] [data-testid='stTabPanel'] [data-testid='stMarkdownContainer']")
.first();stTabPanel already excludes everything before the tab panels in the DOM — CSS injection, success banner, tab labels — so .first() reliably lands on Quick Facts regardless of how many tabs exist or how many pre-tab elements are in the markup.
Why the Healer Chose .nth(4)
The healer’s choice of .nth(4) is worth examining because it illustrates a consistent pattern in agentic code generation: optimising for empirical correctness over structural reasoning.
The healer had no access to git history. The stTabPanel scope wasn’t arbitrary — it was added specifically to handle a Streamlit 1.56 change where tab labels started rendering as stMarkdownContainer elements in the tab bar. This context lives entirely in commit messages and code comments. The healer could read the comment explaining the scope, but comments explain decisions; they don’t reconstruct the reasoning chain that led to them. Without knowing why the stTabPanel scope existed, the healer had no strong reason to preserve it.
Haiku optimises for the shortest path to green. Haiku is a smaller, faster model with a shallower reasoning window than Sonnet. Given a failing locator and a test that needs to pass, the most direct cognitive path is: look at the DOM, count the containers, pick the right one by index. The stTabPanel approach requires reasoning about what the DOM structure might look like in hypothetical future states — adding tabs, restructuring the layout. That kind of forward-projection is more demanding than pattern-matching on the current snapshot.
The healer’s job description doesn’t include future-proofing. The healer prompt instructs: “Prefer minimal changes (better locator, added wait, better assertion).” A change that makes sixteen tests pass is minimal by the prompt’s own definition. The fragility of .nth(4) is a property of future test runs, not the current one. A healer optimising for “make failing tests pass” will not naturally weight that fragility highly.
It was working with a live DOM snapshot, not the DOM semantics. The healer likely used Playwright’s snapshot tools to examine the actual DOM structure, counted markdown containers, arrived at index 4, and validated it empirically. That’s the right approach for debugging a live test — but it produces an index that’s correct for today’s DOM, not a locator strategy that reflects the intended structure.
The analogy is a developer who fixes a broken SQL query by hardcoding the result set they can see today. The query passes the current test. It will break when the data changes, and there’s no indication in the code that it will.
The Prompt Engineering That Reduced Turn Usage
The original healer prompt was open-ended: read the results, read the trace files, use the Playwright MCP tools heavily. With a 25-turn budget and Haiku’s smaller context window, open-ended exploration is expensive. Each turn that reads an irrelevant trace file or spins up an MCP tool session is a turn not available for applying and verifying a fix.
The revised prompt imposes an ordered workflow with skip conditions:
**Turn budget: 25 turns maximum. Be efficient — prefer direct fixes over extensive investigation.**
**Workflow (follow in order, skip steps if the answer is already clear):**
1. Read `test-results/results.json` — get the failed test titles and error messages.
2. If the error message is self-explanatory (e.g. locator not found, timeout,
assertion mismatch), skip to step 4.
3. Only if the root cause is still unclear: read the source file in
`tests/playwright-ts/tests/` for the failing test. Do NOT use MCP trace tools
unless steps 1–3 give no actionable clue.
4. Apply the minimal fix. Edit the file directly.
5. Re-run only the specific failing test(s).
6. Output the Jira comment.The explicit turn budget acknowledgement and the “skip to step 4 if self-explanatory” instruction change the healer’s behaviour noticeably. For a locator failure — where results.json includes the full error message and the expected/actual locator string — step 2’s skip condition fires, and the healer goes directly to reading the source file and applying a fix. For ambiguous failures, it escalates to trace inspection. The healer now completes within 25 turns on most failures.
The Final Workflow Structure
After all the fixes, the workflow runs in this order:
Run Playwright tests
↓ (on any failure)
Upload Playwright report (always)
Upload test-results (on failure) ← original results.json consumed here
Create Jira ticket (on failure) ← ticket exists before healer runs
Annotate with ticket link
↓ (on test failure + ANTHROPIC_API_KEY set)
Run Playwright Healer Agent ← can safely re-run tests
Print healer output (always) ← even on timeout
↓ (on failure + healer succeeded + ticket exists)
Add Healer Comment to JiraThe ordering constraint is the most important structural decision in the whole setup. Moving Jira ticket creation above the healer eliminated the race condition and made the entire pipeline more robust, because each step’s concerns are now clearly separated: the ticket captures the original failure state; the healer operates on its own copy of the world; the comment step connects the two.
Key Takeaways
Agentic CI steps need explicit turn and time limits. An open-ended claude -p "fix this" call will run until it either succeeds or hits an API error. --max-turns N and timeout-minutes: N are not optimisations — they’re safety rails that prevent one healer step from holding up the entire pipeline for twenty minutes or accumulating unexpected API costs.
Output buffering will silently swallow agentic output on timeout. tee doesn’t help if the upstream process buffers its stdout. stdbuf -oL on both sides of the pipe and a separate if: always() step to print the result file are necessary for any meaningful observability into what the agent actually did.
Step ordering matters when agents modify shared state. The healer re-runs the test suite as part of its repair loop. Playwright clears its output directory at the start of every run. Any downstream step that depends on the original test results must run before the healer — not after.
A healer that makes tests pass is not the same as a healer that writes good code. The TC-04 locator fix is the clearest example of this. The healer’s output was accurate, its diagnosis was correct, and its proposed changes would have made all 16 tests pass. One of those changes was also fragile in a way that would have surfaced as a confusing, hard-to-diagnose failure months later. The most useful role for the healer output is as a starting point for a human review — here is what broke, here is why, here is a candidate fix — not as a changes-to-merge-without-inspection artifact.
The optimal locator fix required git history the agent couldn’t see. The stTabPanel scope wasn’t there by accident; it was added to handle a specific Streamlit version change. An agent reading only the current file has no access to that context. It sees a locator that doesn’t work, observes the DOM, and replaces it with something that does work today. Future-proofing the fix requires knowing why the original approach existed — and that knowledge lives in commit messages and historical blame, not in the current file contents.
The Code
The full project is on GitHub: github.com/pyardley/CompanyIntelligence
The relevant files for the CI integration:
.github/workflows/playwright-ts.yml— the full workflow with healer and Jira steps.github/prompts/healer-prompt.md— the healer agent promptscripts/create-jira-failure.js— Jira ticket creation with ADF formatting and attachmentsscripts/add-jira-comment.js— posts healer output as a Jira comment
The Jira integration requires four secrets: JIRA_BASE_URL, JIRA_EMAIL, JIRA_TOKEN, and JIRA_PROJECT_KEY. The healer requires ANTHROPIC_API_KEY. The workflow degrades gracefully when any of these are absent — the Jira step skips if the results file isn’t present; the healer step skips if the API key isn’t set.